
How GPT-4o Voice Works
OpenAI's limited release today of GPT-4o's hyperrealistic voice features showcases how they manage the trick of making conversation happen.
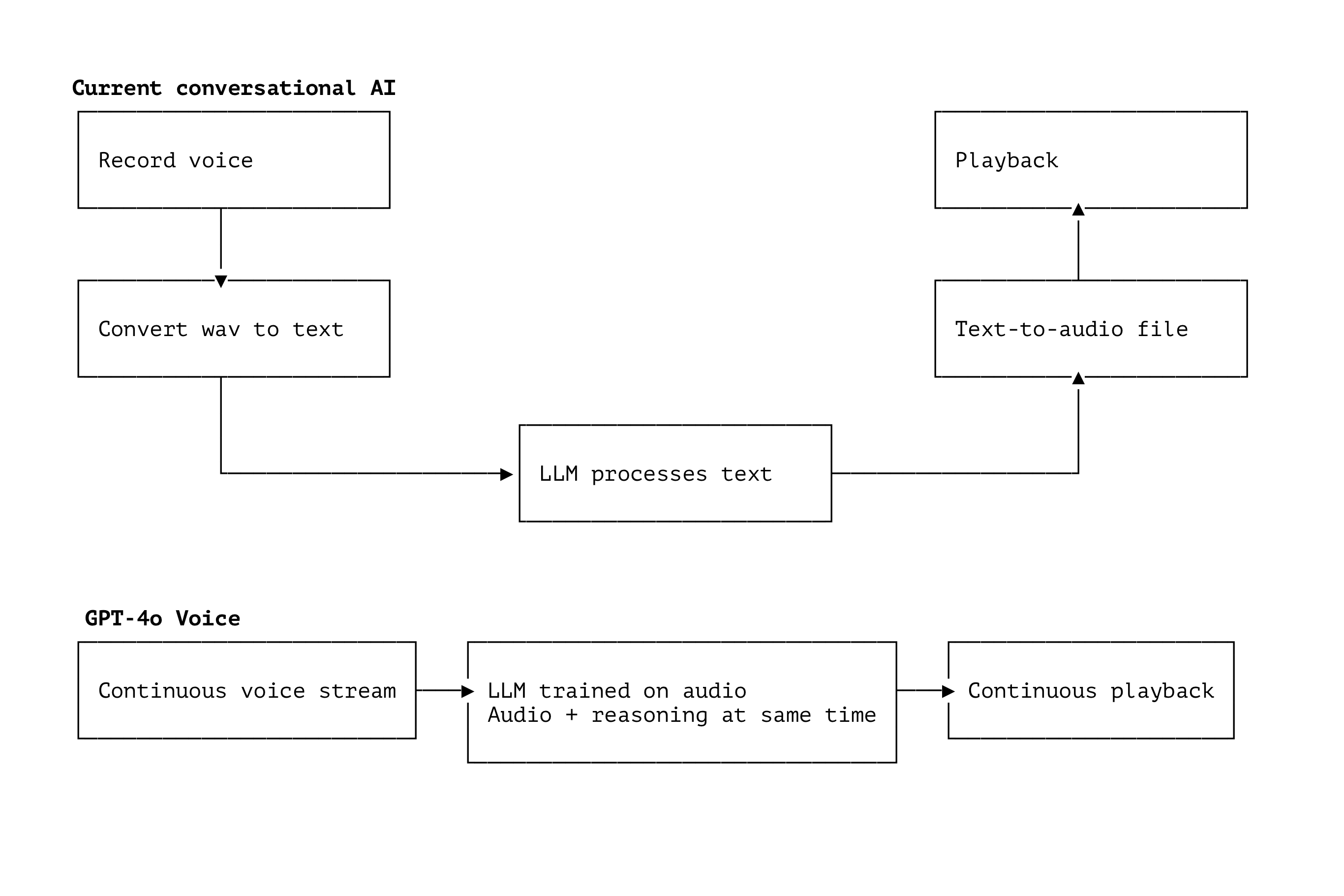
Previously (i.e. NOW for every other AI vendor) a conversation goes like this:
- Your voice is recorded and saved to a file (necessarily requiring you to finish speaking first). Think Alexa, Google assistant, ChatGPT record button etc.
- That audio file gets converted into text using an AI speech-to-text model
- The text version gets process by the LLM (GPT-4, LLaMA 3.1, Claude etc)
- The LLM's text response gets converted into an audio file using an AI text-to-speech model
This whole process is not just time consuming, but importantly for our experience not real time. You can't butt in or converse fluidly. It's like talking to someone on Mars with a 2/3 second delay.
GPT-4o changes all (most) of that by including the 2-way speech models IN the LLM training. That means the LLM can take audio (just like how multimodal LLMs today can accept images) and reply in audio format. This doesn't quite allow butt-ins (it's not a continuous thought process) but greatly reduces latency, with the model running as the audio streams in and outputting "sound" as soon as a response is formed.
Why is this revolutionary? https://www.echowalk.com/blog/ai/gpt-4o-and-the-future-of-call-centres